Waarom deze vraag belangrijk is
In onderzoek naar hersenstoornissen is goede data schaars. Neuropsychiatrische aandoeningen zijn complex, en betrouwbare diagnoses vragen veel verschillende soorten informatie: hersenscans, cognitieve testen, medische voorgeschiedenis en beschrijvende verslaggeving uit dossiers.
Hier ontstaat een unieke mogelijkheid om grote taalmodellen te gebruiken die reeds zijn getraind op enorme hoeveelheden tekst waardoor ze dus al beschikken over brede medische kennis. Ze hoeven niet vanaf nul te leren wat bijvoorbeeld een “geheugenstoornis” of een “frontale afwijking” betekent.
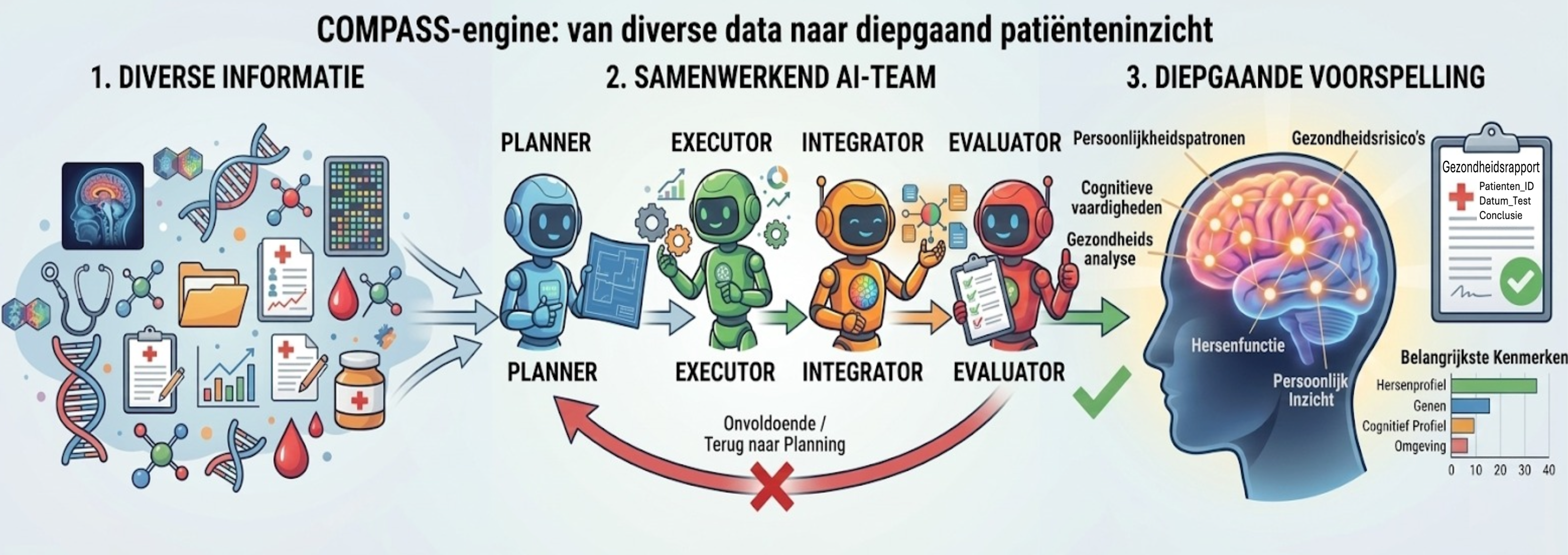
De COMPASS-engine brengt hersengegevens en klinische tekst samen om een beredeneerde inschatting te maken van een neuropsychiatrisch profiel, met een extra controlelaag die denkfouten opvangt.
Onderzoek: de COMPASS-engine in vijf stappen
De onderstaande structuur vat samen hoe onderzoek werd gedaan naar het klinisch nut van deze multi-agentische aanpak binnen de neuropsychiatrie.
-
Data uit verschillende bronnen
Medische data uit de UK Biobank wordt in één vaste structuur gezet. Zowel getallen als tekstvelden worden meegenomen.
Wat gebeurt hier concreet?
De input wordt omgezet naar een uniforme, machine-leesbare structuur zodat elke taalmodel-gebaseerde agent op dezelfde informatiebasis vertrekt (i.e., een ontologie).
-
Referentie voor gezonde patronen
Met brain charts bepalen we eerst wat binnen de gezonde referentie valt. Daarna wordt het per UK Biobank participant zichtbaar waar hun afwijkingen zitten.
Waarom is dit belangrijk?
Het systeem kijkt niet alleen naar groepsgemiddelden, maar naar individuele afwijkingspatronen over het volledige brein.
-
Groepsprofielen voor hersenstoornissen
Neuropsychiatrische en neurologische profielen worden naast elkaar gelegd, inclusief koppeling met genetische, cognitieve en levensstijl kenmerken.
Wat levert dit op?
Een referentiekader waarmee het systeem beter onderscheid kan maken tussen patronen die op CASE of CONTROL wijzen.
-
Taalmodel als redeneerlaag
Grote taalmodellen helpen om patronen uit de deze individuele afwijkingsprofielen samen te vatten en te koppelen aan elkaar via een multi-agent redeneringsproces.
Hoe blijft dit controleerbaar?
De agenten werken met expliciete rollen (planning, analyse, voorspelling, kritiek), zodat redeneringen controleerbaar blijven.
-
Voorlopige resultaten en vervolstappen
Een prototype van de COMPASS-engine kon neuropsychiatrische patiënten met een accuraatheid van 72.5% onderscheiden van de gezonde controle groep.
Wat is de volgende stap?
Verdere externe validatie, strengere foutanalyse en betere calibratie voor uiteenlopende klinische subgroepen.
Conclusie
De COMPASS-engine laat toe om te onderzoeken ofdat een multi-agentisch systeem, bestaande uit grote taalmodellen, een competitief voordeel kan opleveren t.o.v. klassieke voorspellende methoden. De voorlopige resultaten zijn niet sterk genoeg om reeds als definitief besluit te gelden, maar tonen wel duidelijk hun potentieel aan.
Bronnen
1. Bethlehem, R. A. I., Seidlitz, J., White, S. R., Vogel, J. W., Anderson, K. M., & Alexander-Bloch, A. F. (2022). Brain charts for the human lifespan. Nature, 604, 525–533. https://doi.org/10.1038/s41586-022-04554-y
2. Bycroft, C., Freeman, C., Petkova, D., Band, G., Elliott, L. T., & Marchini, J. (2018). The UK Biobank resource with deep phenotyping and genomic data. Nature, 562, 203–209. https://doi.org/10.1038/s41586-018-0579-z
3. Goldshmidt, R., & Horovicz, M. (2024). TokenSHAP: Interpreting large language models with Monte Carlo Shapley value estimation (arXiv:2407.10114). arXiv. https://doi.org/10.48550/arXiv.2407.10114
4. Jeong, D. P., Lipton, Z. C., & Ravikumar, P. (2025). LLM-Select: Feature selection with large language models. Transactions on Machine Learning Research. Advance online publication. https://doi.org/10.48550/arXiv.2407.02694
5. Mansour, S. L., Di Biase, M. A., Smith, R. E., Zalesky, A., & Seguin, C. (2023). Connectomes for 40,000 UK Biobank participants: A multi-modal, multi-scale brain network resource. NeuroImage, 283, Article 120407. https://doi.org/10.1016/j.neuroimage.2023.120407
6. Sundararajan, M., Taly, A., & Yan, Q. (2017). Axiomatic attribution for deep networks (arXiv:1703.01365). arXiv. https://doi.org/10.48550/arXiv.1703.01365
7. Van Severen, S., Diez, I.P., & Cortes, J. M. (2026). COMPASS-engine: Clinical ontology-driven multi-modal predictive agentic support system. Manuscript in preparation.
8. Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., & Rush, A. M. (2020). HuggingFace's Transformers: State-of-the-art natural language processing (arXiv:1910.03771). arXiv. https://doi.org/10.48550/arXiv.1910.03771
9. Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., & Qiu, Z. (2025). Qwen3 technical report (arXiv:2505.09388). arXiv. https://doi.org/10.48550/arXiv.2505.09388